To bridge the gap between written and spoken communication, OpenAI introduced AudioPaLM
Introduction
Have you ever wished you could make your language model not only write, but also speak and listen? OpenAI has made this possible with the introduction of AudioPaLM. This revolutionary language model incorporates audio data into its training process, enabling it to have a more comprehensive understanding of language. By leveraging vast audio datasets that include transcriptions, podcasts, and other spoken content, AudioPaLM has the ability to develop a rich audio-text corpus. In this blog post, we will explore the significance of this advancement in bridging the gap between written and spoken communication.
OpenAI’s goal with AudioPaLM is to enhance the capabilities of language models to not only generate written text but also to interact with users through speech. This breakthrough brings us closer to a future where language models can seamlessly understand and respond to both written and spoken input. By incorporating audio data into the training process, AudioPaLM gains a deeper understanding of the nuances and complexities of spoken language, allowing it to generate more accurate and natural-sounding responses.
Imagine a scenario where you are having a conversation with a language model that not only understands what you write but can also respond by speaking to you. This would revolutionize the way we interact with AI-powered systems, making them more human-like and intuitive to use. With AudioPaLM, OpenAI aims to create a more inclusive and accessible technology by bridging the gap between written and spoken communication.
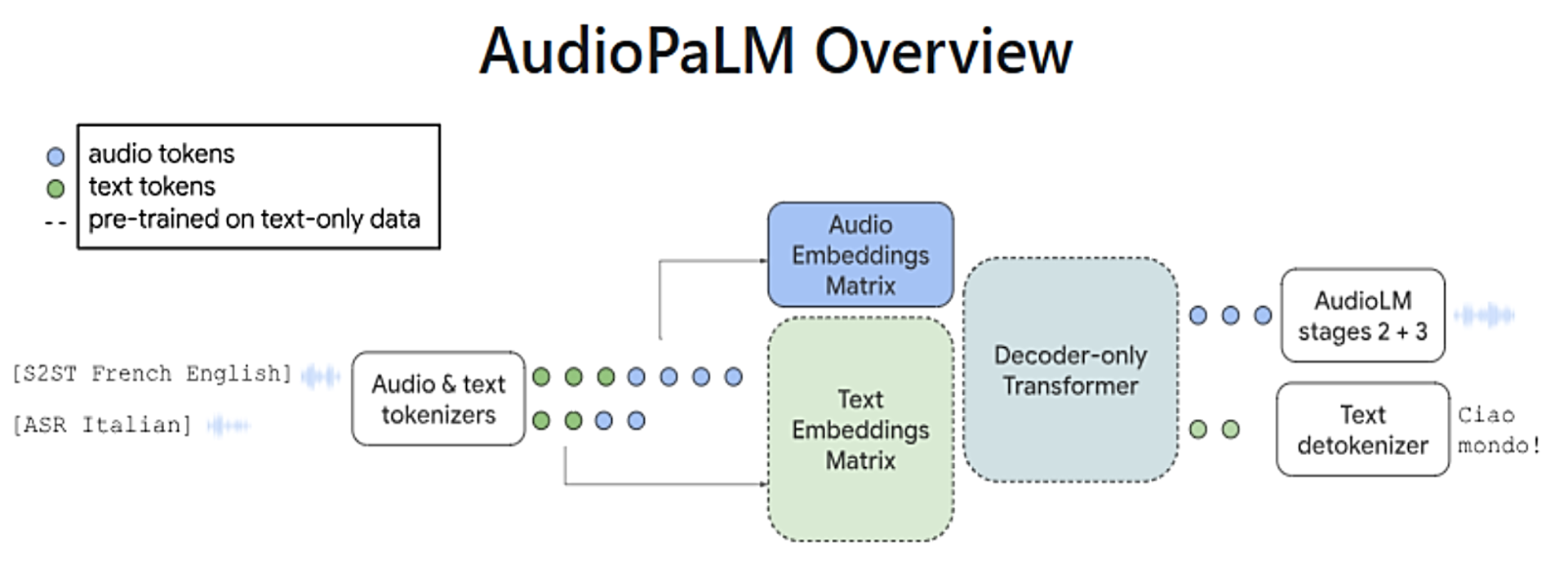
Section 1: The Power of Audio Data
Audio data is a treasure trove of linguistic information. By incorporating audio data into the training process, AudioPaLM gains access to a vast array of spoken language patterns, intonations, and vocal nuances. This allows it to develop a more comprehensive understanding of language, capturing the richness of human communication in all its forms.
One of the key advantages of using audio data is the ability to learn from real-world conversations. By analyzing transcriptions of conversations and podcasts, AudioPaLM can learn how people naturally express themselves in spoken language. This enables the model to generate responses that are not only grammatically correct but also culturally appropriate and contextually relevant.
Furthermore, audio data provides valuable insights into the rhythm, melody, and tone of speech, which are crucial elements in effective communication. By incorporating these aspects into its training process, AudioPaLM can generate responses that mimic the natural flow of spoken language, making interactions with the model feel more authentic and engaging.
Section 2: Bridging the Gap Between Written and Spoken Communication
The introduction of AudioPaLM marks a significant step towards bridging the gap between written and spoken communication. Traditional language models have primarily focused on processing and generating written text, often overlooking the unique characteristics of spoken language. AudioPaLM addresses this limitation by incorporating audio data into its training process, enabling it to understand and generate spoken responses.
Moreover, AudioPaLM allows users to interact with language models using spoken input. Instead of relying solely on written prompts, users can now engage in conversations with the model by speaking to it. This opens up new possibilities for applications such as voice assistants, dialogue systems, and speech-to-text transcription services.
By enabling language models to both speak and listen, OpenAI is making significant strides towards creating a more inclusive and accessible technology. This advancement has the potential to benefit individuals with visual impairments, those who prefer oral communication, and non-native speakers who may find it easier to converse verbally. AudioPaLM brings us closer to a future where language models can seamlessly understand and respond to both written and spoken input, making human-machine interaction more natural and intuitive.
Section 3: The Future of AudioPaLM
OpenAI’s introduction of AudioPaLM is just the beginning of a new era in language modeling. The incorporation of audio data into the training process opens up a myriad of possibilities for further advancements in the field. As more audio datasets become available, the accuracy and effectiveness of language models like AudioPaLM will continue to improve.
The future of AudioPaLM holds promise for applications in various domains. Voice assistants and chatbots can become more conversational and better understand user intent. Language learning platforms can provide more immersive and interactive experiences by allowing learners to practice speaking and listening skills with a language model. Transcription services can benefit from improved accuracy and efficiency by leveraging the enhanced understanding of spoken language.
With AudioPaLM, OpenAI is taking a significant step towards creating language models that can truly bridge the gap between written and spoken communication. By incorporating audio data into the training process, AudioPaLM achieves a more comprehensive understanding of language, enabling it to both speak and listen. This advancement brings us closer to a future where human-machine interaction is seamless, natural, and inclusive.
Recommended: Ashampoo Soundstage: Full Version For Free